You are here: Planning the Model > Steps for Doing Simulation > Step 4: Conducting Experiments > Running Non-terminating Simulations
The issues associated with generating meaningful output statistics for terminating simulations are somewhat different that those associated with generating statistics for non-terminating systems. In steady-state simulations, we must deal with the following issues:
1. Determining the initial warm-up period.
2. Selecting among several alternative ways for obtaining sample observations.
3. Determining run length.
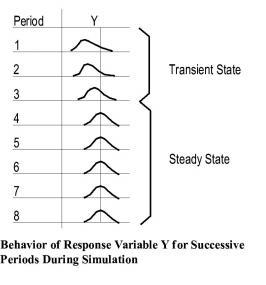
Determining the Warm-up Period In a steady-state simulation, we are interested in the steady-state behavior of the model. Since a model starts out empty, it usually takes some time before it reaches steady-state. In a steady-state condition, the response variables in the system (e.g., processing rates, utilization, etc.) exhibit statistical regularity (i.e., the distribution of these variables are approximately the same from one time period to the next). The following figure illustrates the typical behavior of a response variable, Y, as the simulation progresses through N periods of a simulation.
The time that it takes to reach steady-state is a function of the activity times and the amount of activity taking place. For some models, steady-state might be reached in a matter of a few hours of simulation time. For other models it may take several hundred hours to reach steady-state. In modeling steady-state behavior we have the problem of determining when a model reaches steady-state. This start-up period is usually referred to as the warm-up period. We want to wait until after the warm-up period before we start gathering any statistics. This way we eliminate any bias due to observations taken during the transient state of the model.
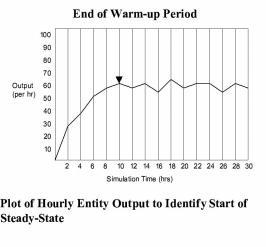
While several methods have been presented for determining warm-up time (Law and Kelton, 1991), the easiest and most straightforward approach, although not necessarily the most reliable, is to run a preliminary simulation of the system, preferably with several (3 to 5) replications, and observe at what time the system reaches statistical stability. The length of each replication should be relatively long and allow even rarely occurring events, such as infrequent downtimes, to occur at least two or three times. To determine a satisfactory warm-up period using this method, one or more key response variables should be monitored by period over time, like the average number of entities in a queue or the average utilization of a resource. This approach assumes that the mean value of the monitored response variable is the primary indicator of convergence rather than the variance, which often appears to be the case. If possible, it is preferable to reset the response variable after each period rather than track the cumulative value of the variable, since cumulative plots tend to average out instability in data. Once these variables begin to exhibit steady-state, we can add a 20% to 30% safety factor and be reasonably safe in using that period as the warm-up period. This approach is simple, conservative and usually satisfactory. Remember, the danger is in underestimating the warm-up period, not overestimating it. Relatively little time and expense is needed to run the warm-up period longer than actually required. The following figure illustrates the average number of entities processed each hour for several replications. Since statistical stability is reached at about 10 hours, 12 to 15 hours is probably a safe warm-up period to use for the simulation.
Obtaining Sample Observations In a terminating simulation, sample observations are made by simply running multiple replications. For steady-state simulations, we have several options for obtaining sample observations. Two widely used approaches are running multiple replications and interval batching. The method supported in ProModel is running multiple replications.
Running multiple replications for non-terminating simulations is very similar to running terminating simulations. The only difference is that (1) the initial warm-up period must be determined, and (2) an appropriate run length must be determined. Once the replications are made, confidence intervals can be computed as described earlier in this chapter. One advantage of running independent replications is that samples are independent. On the negative side, running through the warm-up phase for each replication slightly extends the length of time to perform the replications. Furthermore, there is a possibility that the length of the warm-up period is underestimated, causing biased results.
Interval batching (also referred to as the batch means technique) is a method in which a single, long run is made with statistics being reset at specified time intervals. This allows statistics to be gathered for each time interval with a mean calculated for each interval batch. Since each interval is correlated to both the previous and the next intervals (called serial correlation or autocorrelation), the batches are not completely independent. The way to gain greater independence is to use large batch sizes and to use the mean values for each batch. When using interval batching, confidence interval calculations can be performed. The number of batch intervals to create should be at least 5 to 10 and possibly more depending on the desired confidence interval.
Determining Run Length Determining run length for terminating simulations is quite simple since there is a natural event or time point that defines it for us. Determining the run length for a steady-state simulation is more difficult since the simulation can be run indefinitely. The benefit of this, however, is that we can produce good representative samples. Obviously, running extremely long simulations is impractical, so the issue is to determine an appropriate run length that ensures a sufficiently representative sample of the steady-state response of the system is taken.
The recommended length of the simulation run for a steady-state simulation is dependent upon (1) the interval between the least frequently occurring event and (2) the type of sampling method (replication or interval batching) used. If running independent replications, it is usually a good idea to run the simulation enough times to let every type of event (including rare ones) happen at least a few times if not several hundred. Remember, the longer the model is run, the more confident you can become that the results represent a steady-state behavior. If collecting batch mean observations, it is recommended that run times be as large as possible to include at least 1000 occurrences of each type of event (Thesen and Travis, 1992).